
Forensische integriteit
Hashfuncties zijn een essentieel hulpmiddel om de forensische integriteit van elektronisch opgeslagen informatie te waarborgen en aan te tonen. Hoe werkt een hashfunctie? Waarom is deze zo belangrijk in forensisch onderzoek? En hoe pas je deze toe om de integriteit van digitaal bewijsmateriaal te garanderen? In dit artikel leg ik uit hoe je met hashfuncties de integriteit van digitaal bewijsmateriaal kunt waarborgen en hoe je zelf bestanden kunt verifiëren.
Wat zijn hashfucties
Simpel gezegd is een hashfunctie een wiskundige rekenformule die werkt op basis van input en output. Het zet een bepaalde input om in een unieke reeks van cijfers en letters. Die reeks noemen we de output ofwel de hashwaarde en deze kan worden beschouwd als een unieke digitale vingerafdruk. Veel gebruikte hashfuncties zijn MD5, SHA-1 en SHA-256.
- De input van een hashfunctie is een willekeurige hoeveelheid data. Dit kan een losse tekst, een tekstbestand, een afbeelding of de volledige inhoud van de harde schijf van een computer zijn.
- De output is de hashwaarde, die afhankelijk van de toegepaste hashfunctie een vaste lengte heeft, ongeacht de grootte van de input.
Wat de input ook is, de hashfunctie creëert altijd een output met dezelfde vaste lengte. Echter, verander je iets kleins aan de input, dan ziet de output er compleet anders uit.
Dit wordt duidelijker aan de hand van een voorbeeld. In onderstaande illustratie nemen we een eenvoudige tekst die uit de woorden “Hello World” bestaat en zetten die om met behulp van de MD5 hashfunctie. Vervolgens gebruiken we dezelfde tekst maar is de hoofdletter “W” veranderd in een kleine letter “w”. Zoals je ziet is de berekende hashwaarde compleet anders.
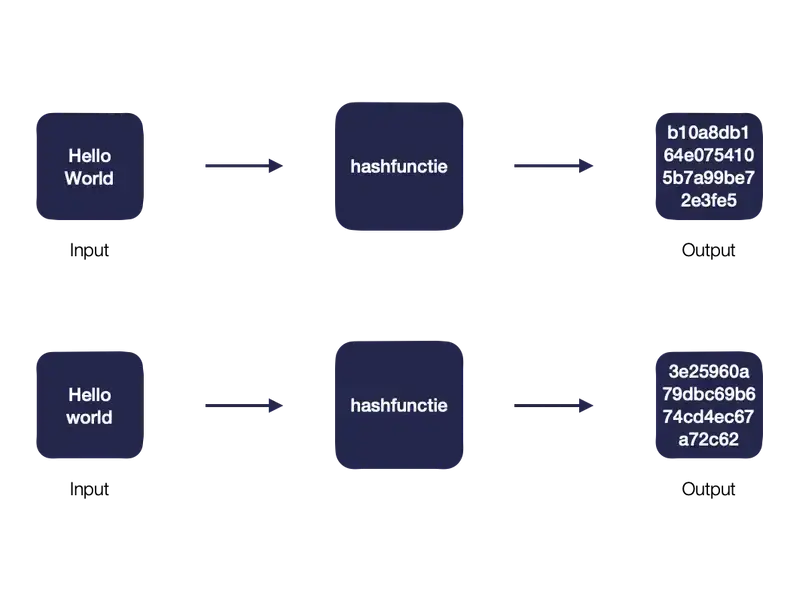
Dit maakt hashfuncties zeer nuttig voor integriteitscontroles omdat zelfs de kleinste verandering in een bestand direct te detecteren is.
Ander voorbeeld, stel je hebt twee versies van een belangrijk digitaal document, bijvoorbeeld een contract of een rapport. Voordat je de documenten print en ondertekend, wil je controleren of ze identiek zijn, zonder handmatig door de hele tekst te hoeven gaan. Met hashfuncties kun je snel en betrouwbaar controleren of de bestanden inhoudelijk van elkaar verschillen zonder ze zelfs maar te hoeven openen.
Dit kan door een hashfunctie toe te passen op de documenten en vervolgens de verkregen hashwaarden met elkaar te vergelijken. Zo kan direct worden aangetoond of een bepaald document exact gelijk is aan het andere document, of juist niet. Aan de hand van een hashwaarde kan in principe iedere specifieke dataset of bestand uniek worden geïdentificeerd.
Voordelen van hashfuncties
- Ze zijn uniek. Zelfs de kleinste verandering of afwijking in de input zal leiden tot een compleet verschillende hashwaarde in de output.
- Hebben een vast formaat / lengte. Ongeacht de grootte of omvang van de input heeft de verkregen hashwaarde altijd dezelfde output lengte.
- Zijn onomkeerbaar. Het is praktisch onmogelijk om de oorspronkelijke invoer te achterhalen vanuit een verkregen hashwaarde.
- Zijn efficiënt. De berekening is snel, zelfs voor grote databestanden en / of opslagmedia.
Hashfuncties en bitlengte
Hashfuncties zijn cryptografische wiskundige algoritmes waarbij de zogenaamde bitlengte aangeeft uit hoeveel tekens (bits) de hashwaarde bestaat die eruit komt. Hoe groter de bitlengte, hoe meer unieke combinaties er mogelijk zijn. De bitlengte bepaalt hoe sterk en uniek de vingerafdruk is die een hashfunctie maakt. Hoe meer bits, hoe veiliger en moeilijker te kraken. Een hashwaarde gegenereerd met een hashfunctie die een bitlengte heeft van 256 bits is dus veel moeilijker te breken dan een hashwaarde van 128 bits.
Als voorbeeld kunnen we een hashwaarde als een kluiscode beschouwen. Stel je voor dat je een hashfunctie gebruikt om een kluiscode te maken. Hoe langer die code, hoe moeilijker het wordt om de juiste te raden.
De MD5 hashfunctie heeft een bitlengte van 128 bits. Dat is als een kluis met 128 knoppen, elke knop kan een 0 of een 1 zijn. Dat geeft zo’n 18,4 triljard mogelijkheden, dat is 1 op 18.400.000.000.000.000.000 mogelijke kluiscombinaties. De SHA-256 hashfunctie heeft een bitlengte van 256 bits, oftewel een kluis met 256 knoppen. Die heeft daarmee 340 undeciljard mogelijkheden. Dat is 340 met 69 nullen erachter!
Simpel gezegd: bij een korte hashwaarde (weinig bits) kan iemand met een krachtige computer sneller gokken wat de kluiscombinatie is. Een langere hashwaarde (veel bits) maakt dat praktisch onmogelijk.
Kwetsbaarheden van hashfuncties
Veruit het grootste risico van hashfuncties is wanneer de input van twee verschillende bestanden dezelfde hashwaarde zou opleveren. In dat geval spreken we van een zogeheten hash collision waardoor de betrouwbaarheid en de forensische integriteit van deze gegevens niet meer gegarandeerd is.
Ondanks dat het risico op hashwaarde collision zeer gering is, blijft er een hele kleine theoretische kans dat dit toch gebeurt. Daarom zijn hashfuncties altijd in ontwikkeling en worden er steeds nieuwe en krachtigere cryptografische algoritmes met langere bitlengtes toegepast.
Zo wordt bijvoorbeeld binnen de advocatuur nog steeds veel gebruik gemaakt van bijvoorbeeld de MD5 en SHA-1 hashfuncties. Binnen digitaal forensisch onderzoek wordt steeds meer gebruik gemaakt van SHA-256 hashfuncties. De SHA-256 hashfunctie maakt simpelweg gebruik van een krachtiger cryptografisch algoritme met een langere bitlengte waardoor het risico op een hashcollision kleiner is. Met name binnen het strafrecht is dit essentieel.
Laten we ook hier eens nader naar kijken. Maar laten we beginnen met de theoretische kans dat er meerdere willekeurige personen op de aarde rondlopen met dezelfde vingerafdruk.
Binnen de forensische literatuur wordt een schatting gehanteerd die stelt dat de kans dat twee willekeurige mensen exact dezelfde vingerafdruk hebben kleiner is dan 1 op 64 miljard. Of voluit geschreven, minder dan 1 op 64.000.000.000.
- Voor de MD5 hashfunctie is de theoretische kans op een hashcollision 1 op 18,4 triljard oftewel 1 op 18.400.000.000.000.000.000.
- De SHA-1 hashfunctie produceert een hashwaarde met een bitlengte van 160 bits. Dit geeft een theoretische kans van ongeveer 1 op 1,2 septiljard, dat is voluit geschreven 1 op 1.200.000.000.000.000.000.000.000.
- SHA-256 geeft een output van 256 bits, hetgeen neerkomt op ongeveer 1 op 340 undeciljard. Oftewel 1 op 340 gevolgd door de eerder genoemde 69 nullen.
Dus ondanks dat de MD5 en SHA-1 hashfuncties nog veelvuldig worden gebruikt, worden ze binnen digitaal forensisch onderzoek als verouderd beschouwd en niet meer bruikbaar voor integriteitscontroles. SHA-256 is op dit moment de hashfunctie die het meest wordt gebruikt al zijn er diverse andere hashfuncties beschikbaar. Daarbuiten voldoen ze voor het controleren of vergelijken van bijvoorbeeld digitale documenten, fotobestanden of e-mail berichten, zijn de MD5 en SHA-1 hashfuncties nog prima. Immers, de kans op 2 willekeurige personen met exact dezelfde vingerafdruk is vele malen groter dan een theoretische hashcollision van de MD5 en SHA-1 hashfuncties.
Zelf aan de slag met hashfuncties
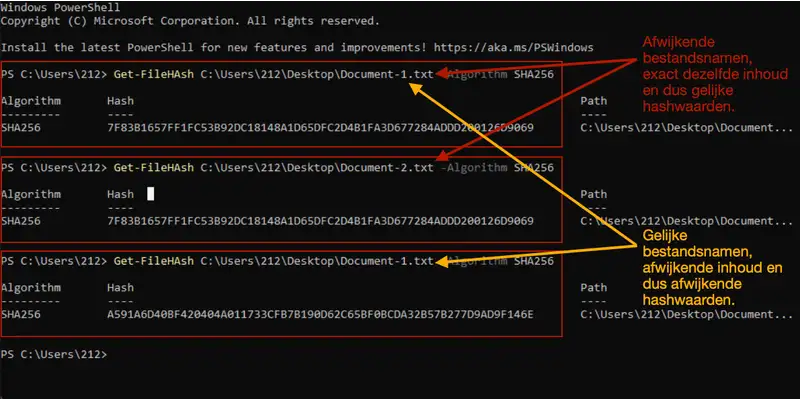
Het is niet moeilijk om zelf integriteitscontroles uit te voeren met behulp van hashfuncties. De meeste computers hebben deze functies min of meer ingebakken in het besturingssysteem en zijn beschikbaar met een eenvoudig commando. Laten we een voorbeeld bekijken waarin we 2 documenten met dezelfde tekstinhoud maar verschillende bestandsnamen verifiëren aan de hand van de SHA-256 hashfunctie.
Hiervoor gebruiken we een op Windows gebaseerde computer en maken in eerste instantie in Notepad een tekstbestand aan met daarin de tekst “Hello World!”. Dit bestand bewaren we op de Desktop van de computer onder de naam Document-1.txt. We slaan vervolgens hetzelfde bestand nogmaals op onder de naam Document-2.txt.
Willen we de SHA-256 hashfunctie toepassen dan kan dat simpelweg als volgt:
- Start het programma PowerShell.
- Voer het commando Get-FileHash in gevolgd door de locatie- en bestandsnaam van het bestand waarop je de hashfunctie wil toepassen en kies vervolgens voor hashfunctie -Algorithm SHA256. Enter en klaar, de berekende hashwaarde wordt in het terminal scherm weergegeven. Zie voor de berekende hashwaarden de afbeelding hieronder. Enter en klaar, de berekende hashwaarde wordt in het terminal scherm weergegeven.
Get-FileHash C:\Users\gebruikersnaam\Desktop\Document-1.txt -Algorithm SHA256
- Vervolgens berekenen we de hashwaarde van het 2e document op dezelfde manier, met hetzelfde commando, maar het gedupliceerde bestand met bestandsnaam Document-2.txt. De inhoud van beide bestanden is exact gelijk, ondanks dat ze niet dezelfde bestandsnaam hebben. De berekende hashwaarde is daardoor ook exact gelijk.
Get-FileHash C:\Users\gebruikersnaam\Desktop\Document-2.txt -Algorithm SHA256
- Als laatste verwijderen we het uitroepteken in een van de documenten en slaan het op in een andere folder op de computer maar wederom met bestandsnaam Document-1.txt. Vervolgens berekenen we de hashwaarde van het document, waarvan we het uitroepteken uit de tekst hebben verwijderd maar opgeslagen onder de originele bestandsnaam Document-1.txt. We krijgen dan een compleet afwijkende hashwaarde. De documenten zijn qua inhoud verschillend ondanks dat ze dezelfde bestandsnaam hebben. De berekende hashwaarde is daardoor compleet anders ondanks dat er inhoudelijk maar 1 leesteken is gewijzigd.
Dit maakt hashfuncties niet alleen een krachtig hulpmiddel binnen digitaal forensisch onderzoek, maar ook ten behoeve van documentbeheer, software applicatiebeheer of digitale contracten. Het stelt ons in staat snel en efficiënt na te gaan of bestanden zijn gewijzigd, zonder ze handmatig inhoudelijk te moeten vergelijken.
Conclusie
Hashfuncties zijn cruciaal binnen digitaal forensisch onderzoek. Ze helpen om de integriteit van digitaal bewijsmateriaal te waarborgen en aan te tonen. Ze zijn eenvoudig toe te passen met tools die standaard beschikbaar zijn in elk besturingssysteem.
De uit hashfuncties verkregen hashwaarden zijn eenrichtingsverkeer, je kunt ze niet terugdraaien naar de originele data. Hashberekeningen zijn uit te voeren op bijna alle soorten digitale informatie, van kleine bestanden tot volledige opslagmedia. Een verkregen hashwaarde is qua lengte altijd gelijk.
Hashfuncties spelen daarmee een sleutelrol in verschillende situaties, van digitaal forensisch onderzoek, document beheer en malwaredetectie tot blockchaintechnologie en wachtwoordbeheer. Door de juiste methoden en sterke hashfuncties te gebruiken, kun je ervoor zorgen dat digitaal bewijsmateriaal betrouwbaar en onbetwist is, en blijft.
Heb je vragen over dit onderwerp, neem dan gerust contact op via het contactformulier op de website of volg 212 op Linkedin.